World Model Self-Distillation: Training World Models to Solve General Tasks
arXiv, 2026
A new way to train task-solving video world models without paired demonstrations.

I am a Postdoctoral Researcher in the Computer Vision Group at the University of Bern. I earned my Ph.D. in Computer Science from the University of Bern in 2024, where I was supervised by Prof. Dr. Paolo Favaro. Prior to that, I completed a Specialist degree (equivalent to B.S. + M.S.) in Fundamental Mathematics and Mechanics at MSU in 2020. Additionally, I graduated from YSDA in 2018. My research interests include Machine Learning, Computer Vision, Generative AI, and World Models.

A new way to train task-solving video world models without paired demonstrations.

A new way to represent images as discrete sequences of tokens by sequentially integrating information from image crops, yielding semantically meaningful structured representations.
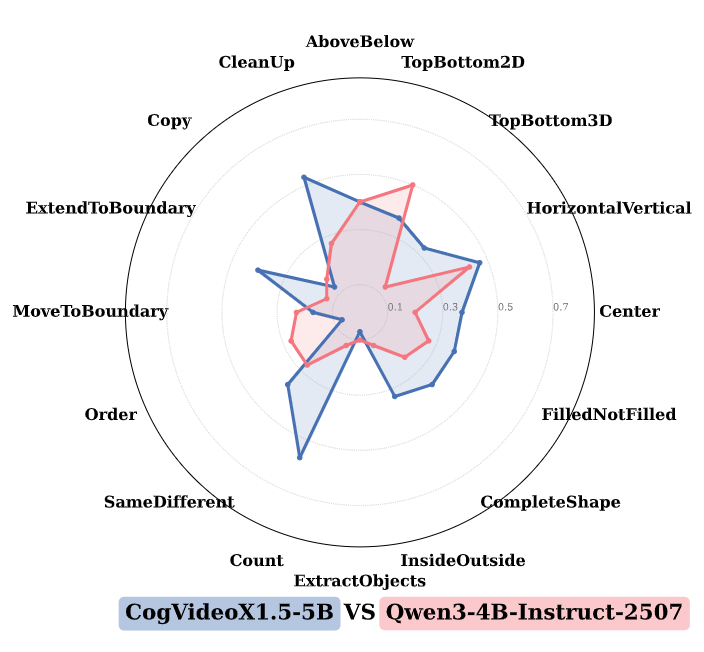
The second version of the Gen2Gen paper, in which we demonstrate that VDMs are more data efficient than LLMs in learning new visual tasks.

A diffusion-based world modeling framework that integrates heterogeneous memory models through a contrastive product-of-experts formulation.
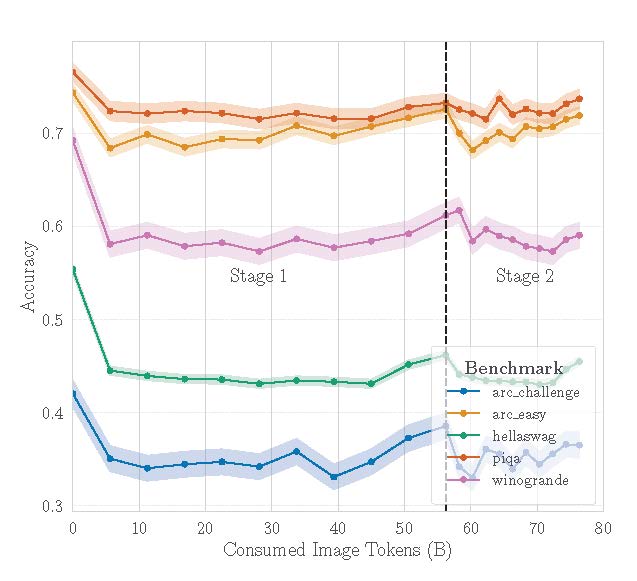
Unpaired image adaptation of a pre-trained language model followed by lightweight image–text alignment enables multimodal understanding while preserving language capabilities.

A few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples.
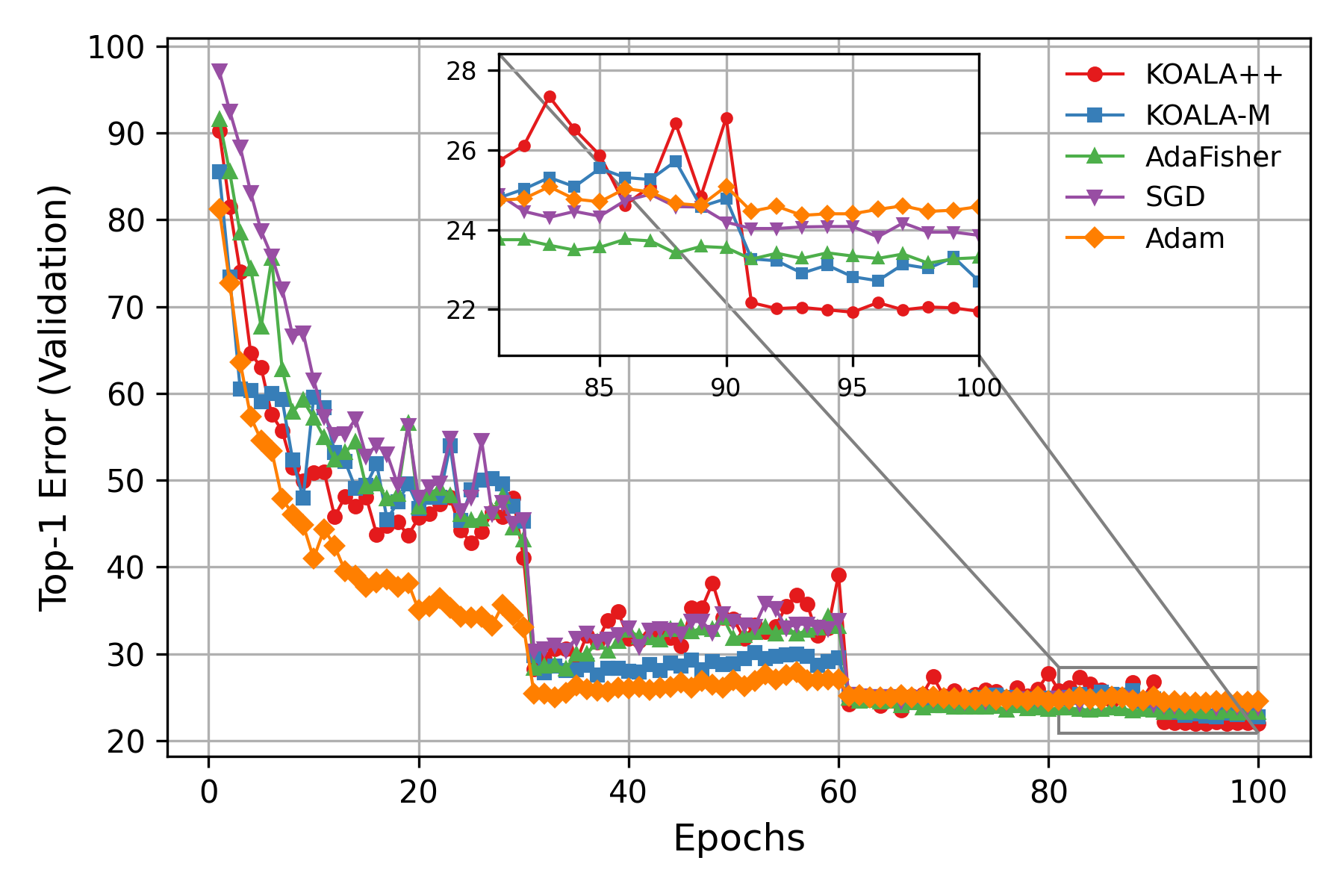
An extension of KOALA, a neural network optimization algorithm based on Kalman filtering, with implicit full weights covariance matrix.

Single image to novel view synthesis without any supervision.
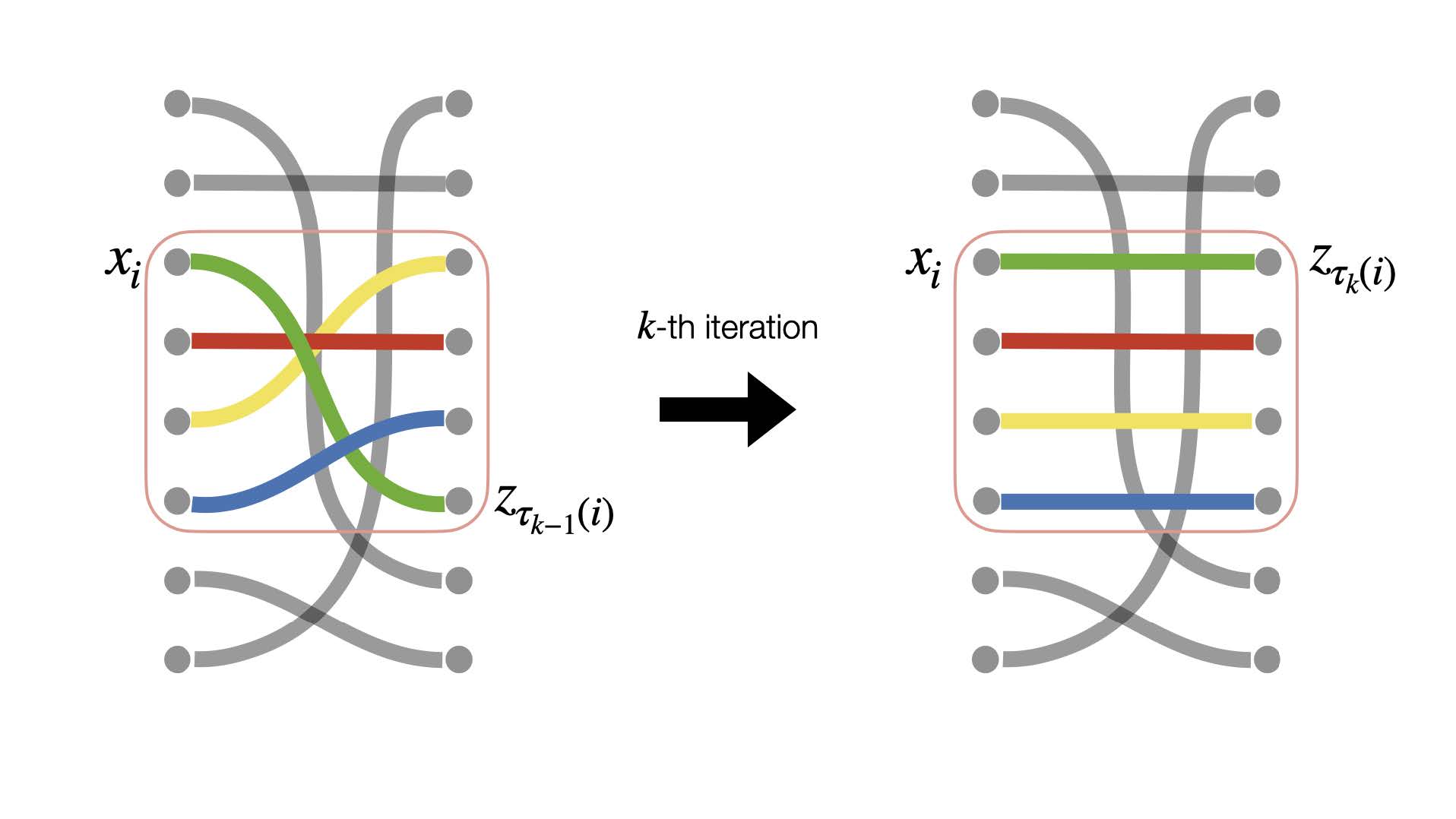
A method that straightens sampling trajectories in the flow matching framework via storing and exchanging locally optimal data-noise couplings across minibatches.

A multi-modal and multi-domain ego-vision world model with precise control over object dynamics, ego-agent motion and human poses.
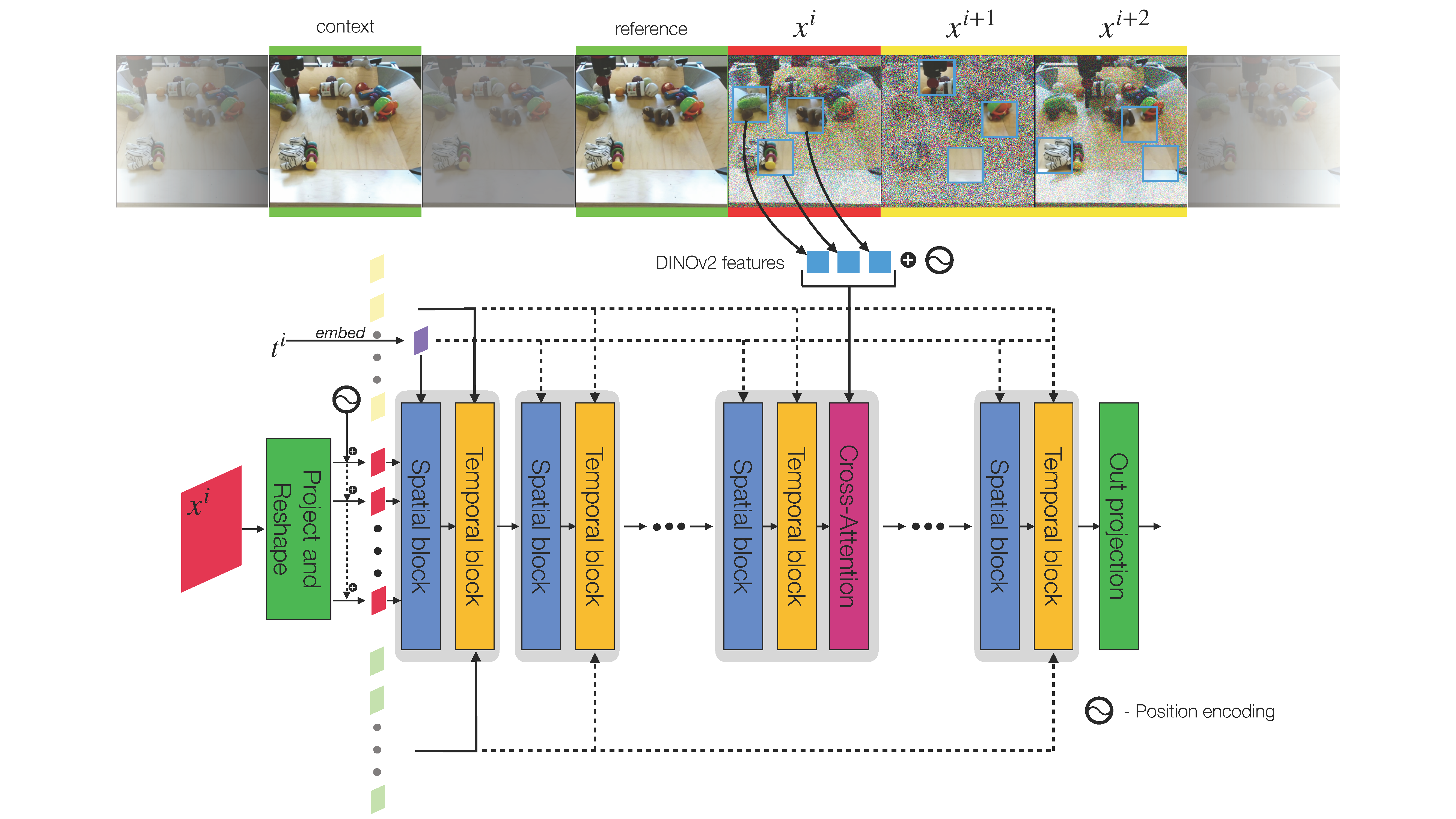
A model to compose and animate scenes from sparse sets of visual features.

A model to animate single frames with sparse motion control.
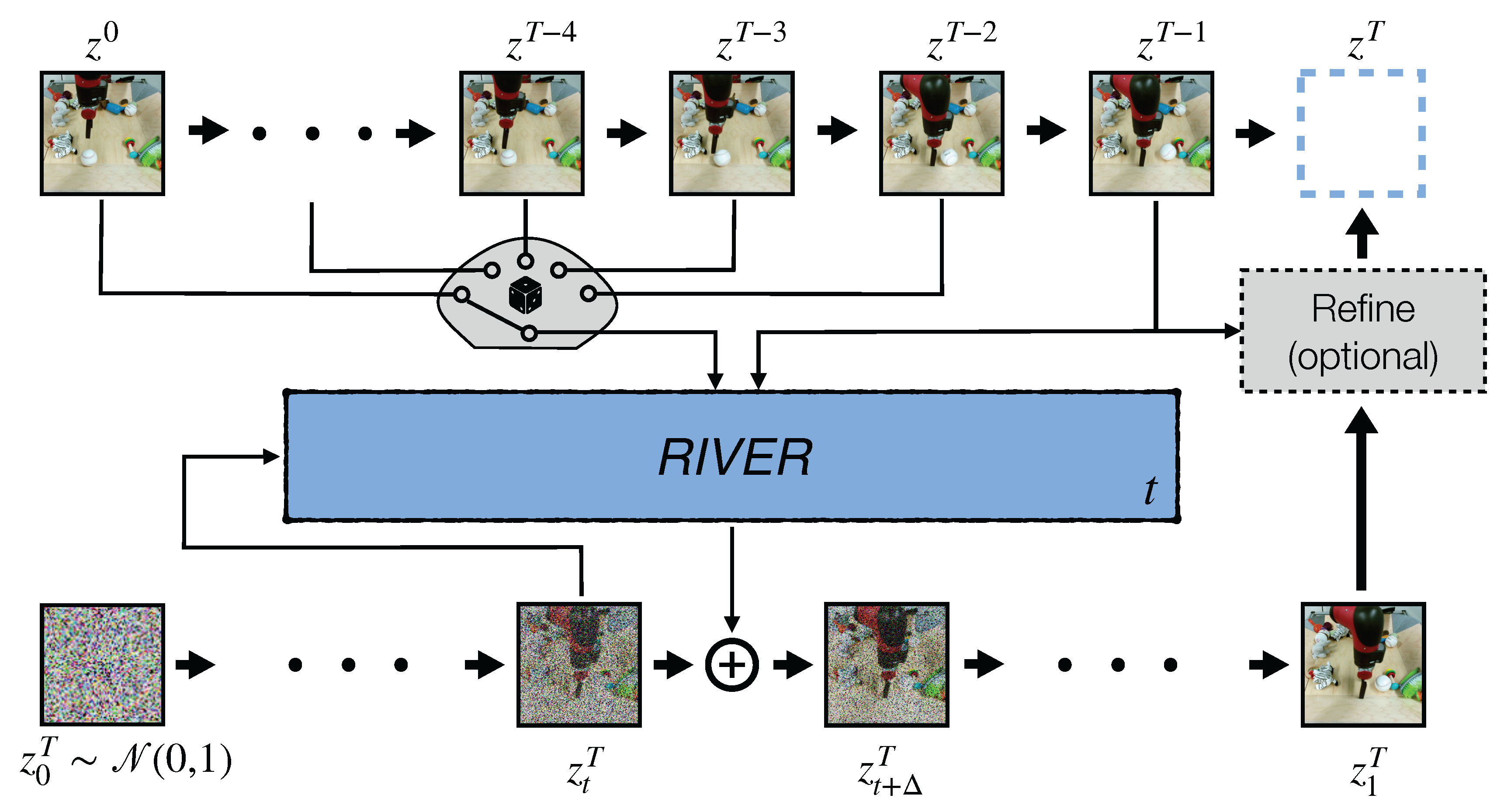
Conditioning only on a few randomly chosen past frames at each denoising step of flow matching results into a more efficient training procedure.

A model to discover agents' action spaces from a dataset of videos in an unsupervised way. The action spaces are decomposed into global (2D shifts) and local (discrete) actions.
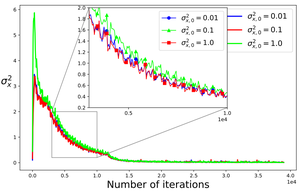
A neural network optimization algorithm based on Kalman filtering.