World Model Self-Distillation is now available on arXiv.
Aram Davtyan
I am a Postdoctoral Researcher in the Computer Vision Group at the University of Bern, working on generative AI, controllable video generation, and world models. I am especially interested in models that learn reusable world representations from the visual experience, going beyond plausible synthesis to support couterfactual intervention, generalization, visual intelligence, adaptation to new tasks, and beyond. I earned my Ph.D. in Computer Science from the University of Bern in 2024, advised by Prof. Dr. Paolo Favaro. Before that, I completed a Specialist degree in Fundamental Mathematics and Mechanics at Lomonosov Moscow State University and studied data analysis at YSDA.
News
Recent Updates
COMiT introduces a compact, structured image representation built from sequential crop aggregation.
Received an ARC Prize Honorable Mention for research on repurposing video diffusion models for novel visual and logic tasks.
I gave a talk during the Swiss AI Weeks introducing GEM and other works built using the Swiss AI compute.
Started as a Postdoc in the Computer Vision Group at the University of Bern.
Successfully defended my PhD at the University of Bern! (Thesis)
Publications

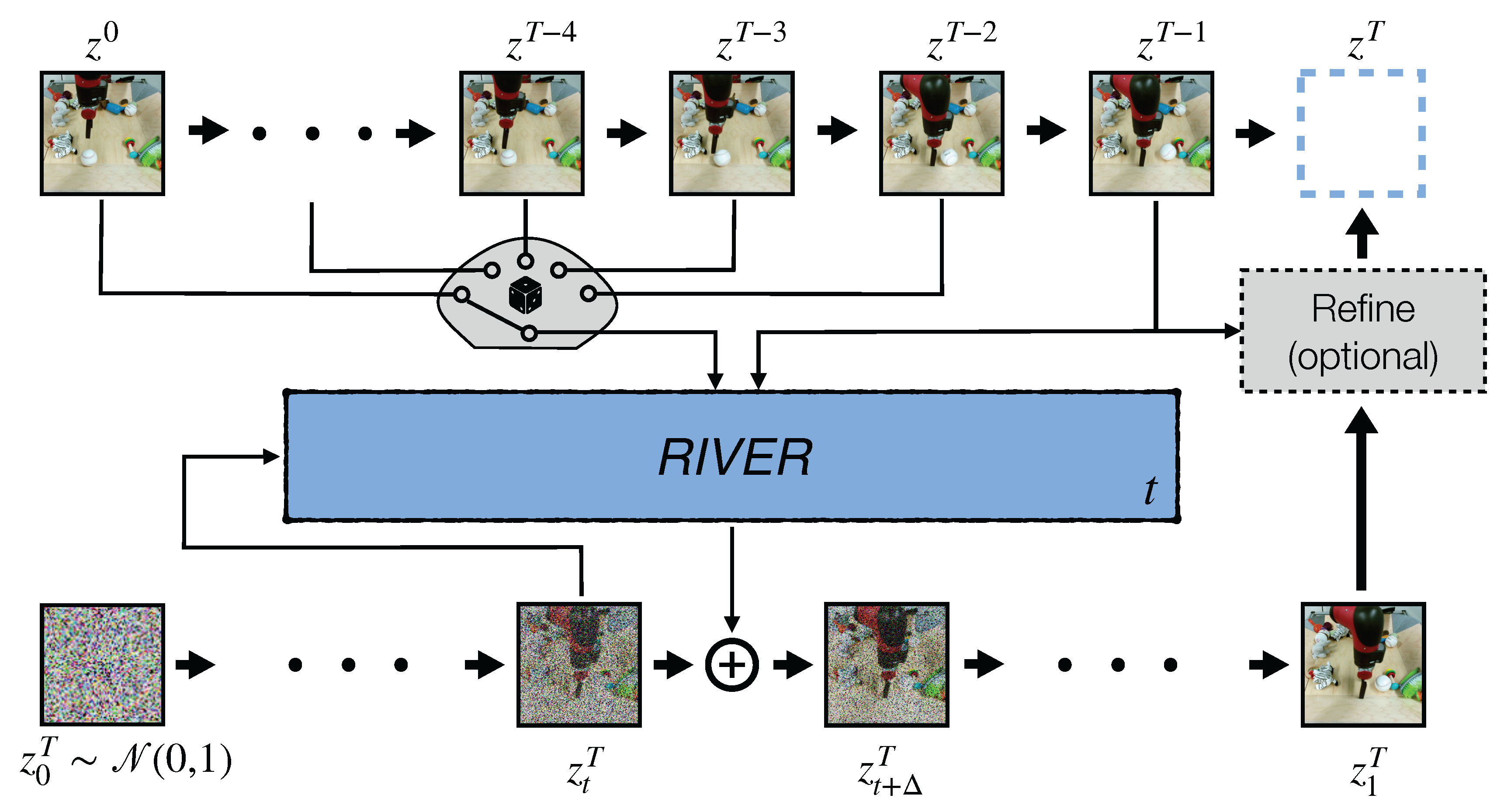
World Model Self-Distillation: Training World Models to Solve General Tasks
A new way to train task-solving video world models without paired demonstrations.
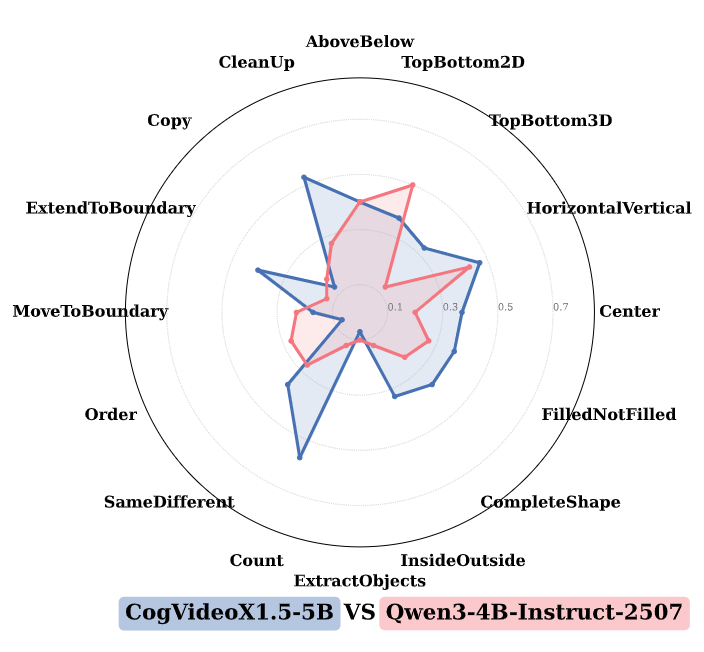
Rethinking Visual Intelligence: Insights from Video Pretraining
The second version of the Gen2Gen paper, in which we demonstrate that VDMs are more data efficient than LLMs in learning new visual tasks.
ARC Prize 2025 Honorable Mention.

Composition of Memory Experts for Diffusion World Models
A diffusion-based world modeling framework that integrates heterogeneous memory models through a contrastive product-of-experts formulation.

Communication-Inspired Tokenization for Structured Image Representations
A new way to represent images as discrete sequences of tokens by sequentially integrating information from image crops, yielding semantically meaningful structured representations.
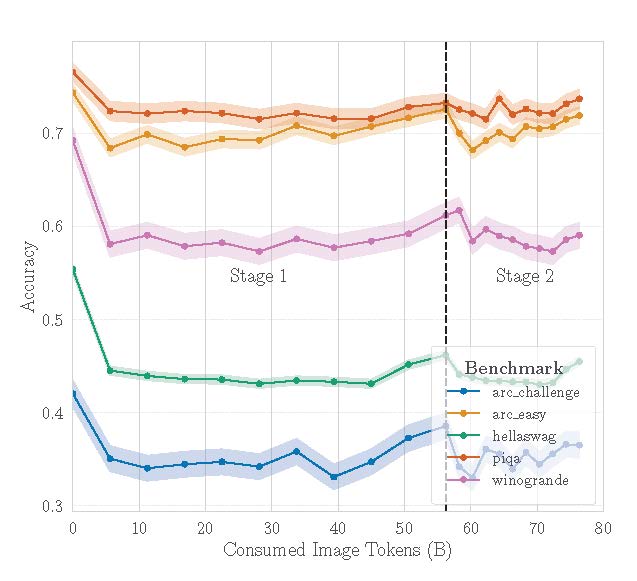
Learning Vision-Language Alignment in Unified LLMs with 24 Text Tokens per Image
Unpaired image adaptation of a pre-trained language model followed by lightweight image–text alignment enables multimodal understanding while preserving language capabilities.

From Generation to Generalization: Emergent Few-Shot Learning in Video Diffusion Models
A few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples.
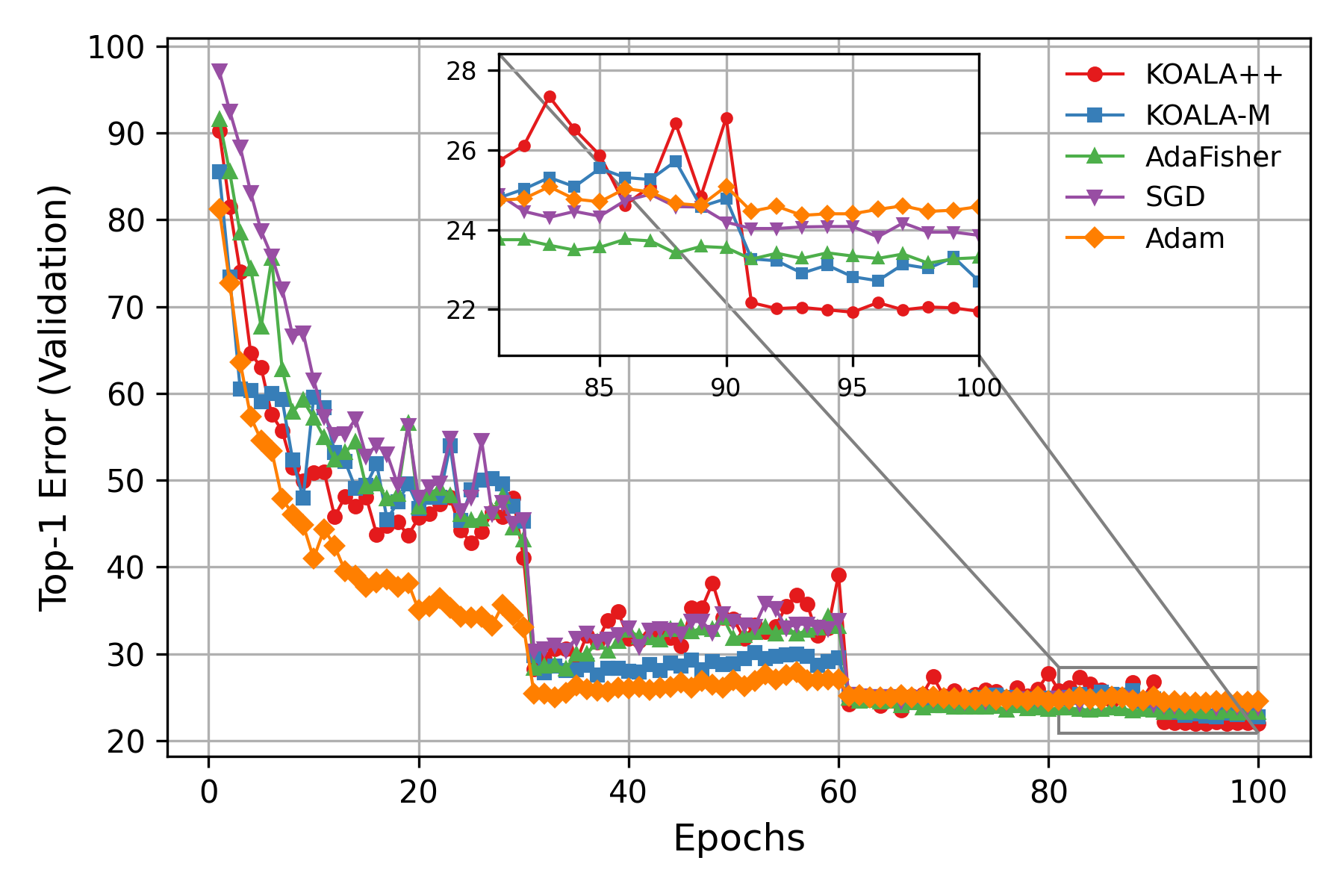
KOALA++: Efficient Kalman-Based Optimization of Neural Networks with Gradient-Covariance Products
An extension of KOALA, a neural network optimization algorithm based on Kalman filtering, with implicit full weights covariance matrix.

MIRAGE: Unsupervised Single Image to Novel View Generation with Cross Attention Guidance
Single image to novel view synthesis without any supervision.
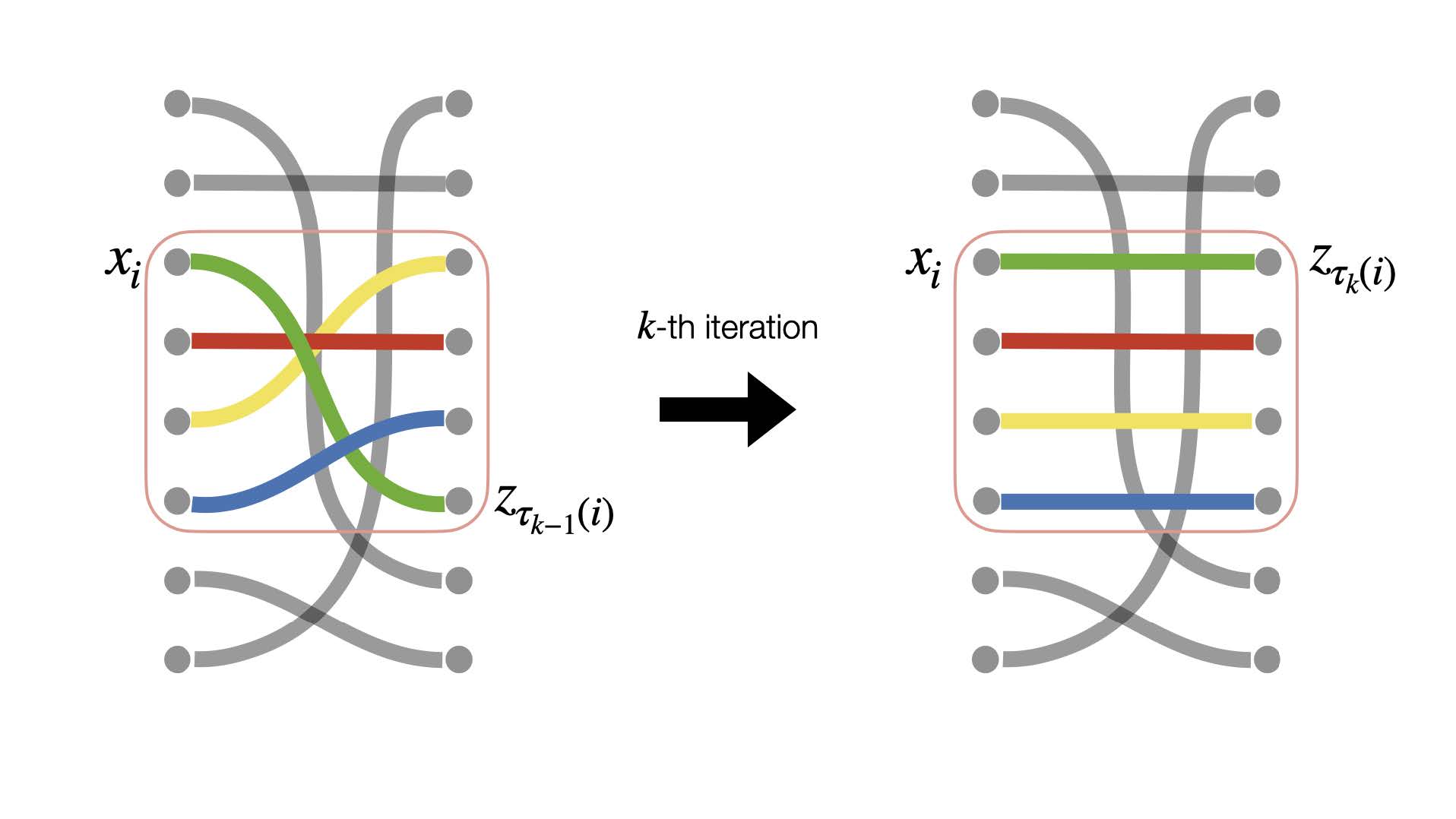
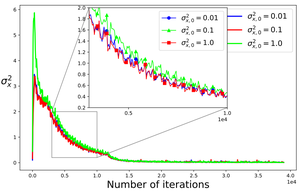
Faster Inference of Flow-Based Generative Models via Improved Data-Noise Coupling
A method that straightens sampling trajectories in the flow matching framework via storing and exchanging locally optimal data-noise couplings across minibatches.

GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
A multi-modal and multi-domain ego-vision world model with precise control over object dynamics, ego-agent motion and human poses.
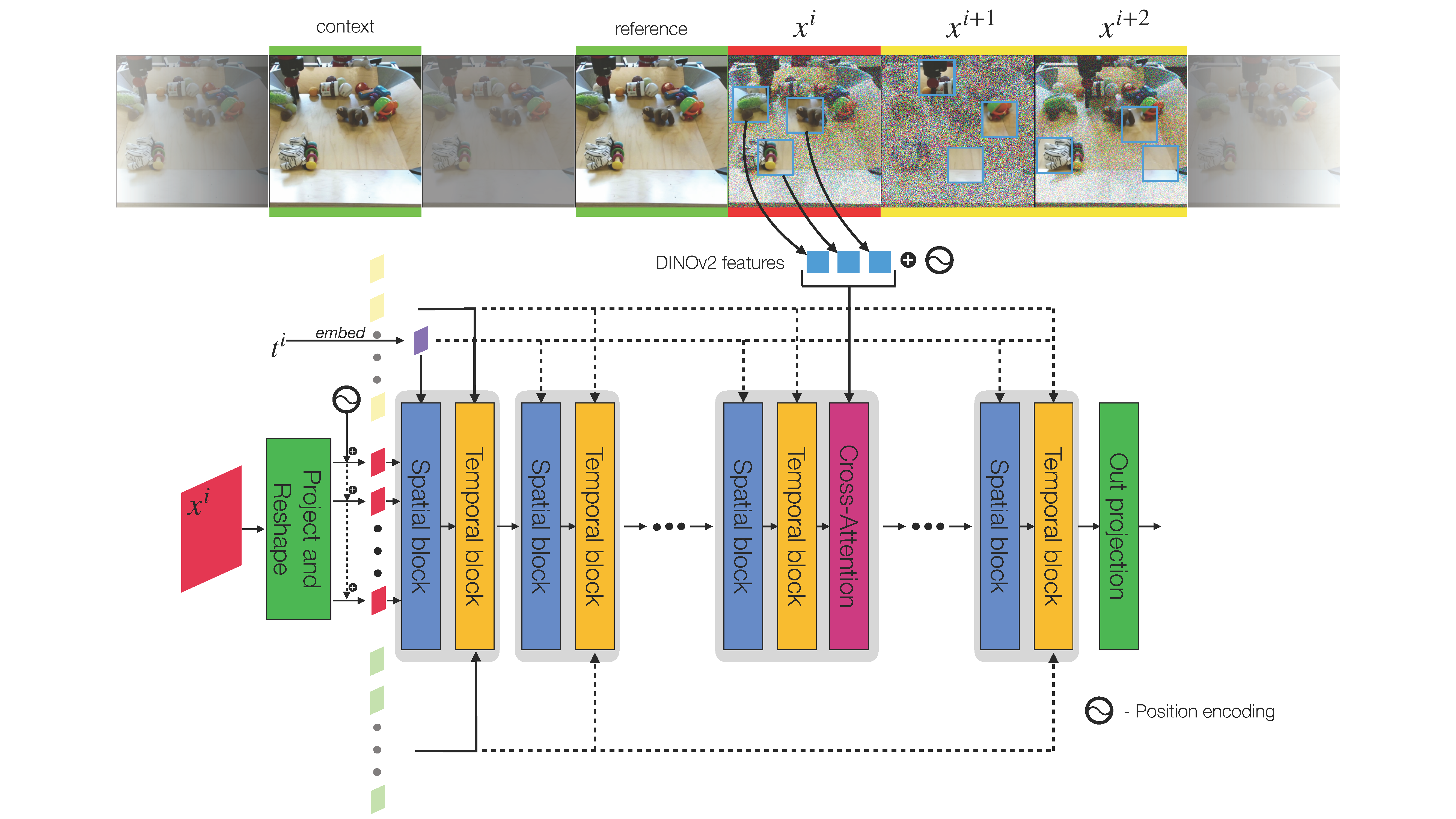
CAGE: Unsupervised Visual Composition and Animation for Controllable Video Generation
A model to compose and animate scenes from sparse sets of visual features.

Learn the Force We Can: Enabling Sparse Motion Control in Multi-Object Video Generation
A model to animate single frames with sparse motion control.
Efficient Video Prediction via Sparsely Conditioned Flow Matching
Conditioning only on a few randomly chosen past frames at each denoising step of flow matching results into a more efficient training procedure.

Controllable Video Generation through Global and Local Motion Dynamics
A model to discover agents' action spaces from a dataset of videos in an unsupervised way. The action spaces are decomposed into global (2D shifts) and local (discrete) actions.
KOALA: A Kalman Optimization Algorithm with Loss Adaptivity
A neural network optimization algorithm based on Kalman filtering.
Talks
Invited Talks and Presentations
Swiss AI Initiative: Our Experience at Computer Vision Group @ UniBE
AI for SMEs: What can small businesses really do with artificial intelligence?, Swiss AI Weeks, Bern
Unsupervised Controllable Video Generation
Invited Seminar, Computer Vision and Geometry Group, ETH Zurich, Zurich
Efficient Video Prediction via Sparsely Conditioned Flow Matching
Nectar Track Oral Presentation, GCPR 2023, Heidelberg
Teaching
Courses
Lecturer
Seminar Machine Learning and Artificial Intelligence | University of Bern
Lecturer
Foundations of Deep Learning | University of Bern
Teaching Assistant
Deep Learning | University of Bern
Teaching Assistant
Machine Learning | University of Bern
Teaching Assistant
Seminar Self-Supervised Learning in Computer Vision | YSDA
Teaching Assistant
Advanced Topics in Machine Learning | University of Bern
Awards
Dec 2025
ARC Prize Honorable Mention
Recognized for research showing that video diffusion models can be repurposed to solve novel visual and logic tasks from only a handful of examples.
Service
Reviewer
ICLR, ICML, CVPR, NeurIPS, ICCV, ECCV